
OCR Tesseract là một trong những công cụ nhận dạng ký tự quang học mã nguồn mở phổ biến nhất hiện nay, đặc biệt với các dự án cần giải pháp miễn phí, chạy offline và dễ tùy chỉnh. Dù xuất hiện nhiều công nghệ OCR mới, Tesseract vẫn giữ vai trò quan trọng trong xử lý tài liệu scan, hóa đơn và văn bản tiếng Việt.
Tóm tắt nhanh: OCR Tesseract là công cụ nhận dạng ký tự quang học mã nguồn mở, miễn phí, chạy offline, dùng để trích xuất văn bản từ ảnh, file scan và PDF. Vì sao OCR Tesseract vẫn được dùng?
Ưu & nhược điểm nhanh
Khi nào nên dùng OCR Tesseract?
Khi nào nên dùng công cụ khác?
Insight cốt lõi: Tesseract phù hợp khi cần OCR miễn phí, offline và kiểm soát dữ liệu; không phải lựa chọn tối ưu cho bài toán OCR tiếng Việt phức tạp trong doanh nghiệp. |
OCR Tesseract là một trong những công cụ nhận dạng ký tự quang học (Optical Character Recognition - OCR) mã nguồn mở mạnh mẽ và phổ biến nhất hiện nay (tính đến năm 2026). Công cụ này cho phép máy tính đọc, phân tích và trích xuất văn bản từ hình ảnh, biến nội dung không thể chỉnh sửa (ảnh chụp, bản scan) thành văn bản số có thể tìm kiếm, sao chép và xử lý.
Nói một cách đơn giản, Tesseract OCR giúp máy tính “hiểu” chữ viết xuất hiện trong:
Tại Việt Nam, OCR Tesseract được ứng dụng rộng rãi trong nhiều bài toán thực tế, tiêu biểu như:
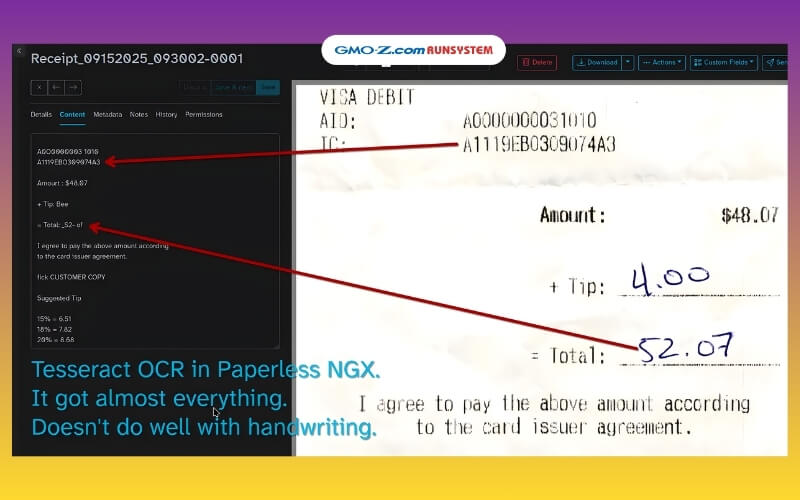
OCR Tesseract là một trong những công cụ nhận dạng ký tự quang học mã nguồn mở mạnh mẽ và phổ biến nhất hiện nay
Tesseract OCR vẫn là một trong những công cụ OCR mã nguồn mở được sử dụng rộng rãi, nhưng không phải lựa chọn “toàn diện” so với các giải pháp mới hơn như PaddleOCR, EasyOCR, VietOCR hay các mô hình dựa trên Transformer / mô hình ngôn ngữ lớn. Dưới đây là tổng hợp ưu - nhược điểm dựa trên các đánh giá giai đoạn 2025-2026.
import cv2
import pytesseract
# Đọc ảnh và xử lý OCR
img = cv2.imread('hoadon.jpg')
text = pytesseract.image_to_string(img, lang='vie')
print(text)
Tóm lại, Tesseract OCR mạnh ở tính miễn phí, offline, ổn định và dễ tùy chỉnh, nhưng kém cạnh tranh hơn các công cụ hiện đại trong những bài toán phức tạp hoặc yêu cầu độ chính xác cao ngay khi cài đặt.

Ưu - Nhược điểm của mã nguồn mở
Tesseract vẫn phù hợp trong nhiều trường hợp nhờ miễn phí, chạy offline, dễ tùy chỉnh và hoạt động tốt trên CPU. Tuy nhiên, đến năm 2026, các công cụ OCR thế hệ mới dựa trên học sâu hiện đại (mạng tích chập CNN kết hợp Transformer) thường vượt trội về độ chính xác khi dùng ngay, khả năng xử lý bố cục phức tạp và văn bản trong ảnh chụp thực tế. Bạn nên cân nhắc chuyển sang công cụ mới khi gặp các tình huống sau:
Tesseract thường phải tiền xử lý ảnh kỹ và cấu hình phức tạp mới đạt kết quả tốt. Trong khi đó, PaddleOCR hoặc VietOCR cho độ chính xác cao hơn rõ rệt ngay khi cài đặt, đặc biệt với hóa đơn và chứng từ tiếng Việt.
Tesseract xử lý chưa tốt bảng biểu nhiều cột, chữ xoay góc hay văn bản trong ảnh chụp thực tế. Các công cụ mới hỗ trợ nhận diện bảng, tự động chỉnh góc và xử lý tốt văn bản ngoài môi trường scan.
Với tiếng Việt, Tesseract mặc định chỉ ở mức trung bình và cần huấn luyện thêm. VietOCR và PaddleOCR cho kết quả chính xác hơn với chữ có dấu và font đặc thù ngay khi sử dụng.
Tesseract chỉ hỗ trợ chạy trên CPU, không tận dụng GPU cho suy luận như các OCR deep learning hiện đại, nên chậm khi khối lượng lớn. Các công cụ mới tận dụng GPU giúp xử lý nhanh hơn nhiều và phù hợp với hệ thống vận hành quy mô lớn.
Tesseract không mạnh với ảnh nhiễu, mờ hoặc chữ viết tay. Các công cụ OCR mới và mô hình nhận dạng dựa trên mô hình ngôn ngữ thị giác cho kết quả ổn định hơn trong bối cảnh thực tế.
Nếu bạn cần trích xuất bảng, cặp khóa - giá trị, hiểu cấu trúc tài liệu hoặc tự động nhận diện đa ngôn ngữ, các công cụ OCR mới đáp ứng tốt hơn mà không cần lập trình bổ sung.
Tóm lại,Tesseract phù hợp với bài toán đơn giản, chi phí thấp và kiểm soát dữ liệu. Ngược lại, với yêu cầu độ chính xác cao, tốc độ nhanh và tài liệu phức tạp, các công cụ OCR thế hệ mới là lựa chọn hiệu quả hơn trong năm 2026.
Bảng so sánh các giải pháp OCR phổ biến
Tiêu chí | Tesseract | PaddleOCR | VietOCR |
Công nghệ | OCR truyền thống + LSTM | Deep Learning (CNN + Transformer) | Deep Learning (CRNN + Transformer) |
Độ chính xác khi cài đặt mặc định | Trung bình | Cao | Cao (đặc biệt với tiếng Việt) |
Hỗ trợ tiếng Việt | Có nhưng cần tinh chỉnh hoặc huấn luyện thêm | Tốt | Rất tốt |
Xử lý bố cục phức tạp | Hạn chế | Tốt (có text detection + layout) | Trung bình |
Nhận diện bảng và nhiều cột | Hạn chế | Tốt | Hạn chế |
Xử lý ảnh chụp thực tế | Trung bình | Tốt | Tốt |
Hỗ trợ GPU | Không | Có | Có |
Tốc độ xử lý dữ liệu lớn | Chậm hơn (CPU) | Nhanh khi dùng GPU | Nhanh khi dùng GPU |
Nhận diện chữ viết tay | Yếu | Trung bình | Trung bình |
Độ dễ triển khai | Dễ | Trung bình | Trung bình |
Chi phí | Miễn phí, mã nguồn mở | Miễn phí, mã nguồn mở | Miễn phí, mã nguồn mở |

OCR Tesseract phù hợp với bài toán đơn giản, chi phí thấp và kiểm soát dữ liệu
Đến năm 2026, Tesseract vẫn được dùng rộng rãi nhờ miễn phí và chạy offline, nhưng đòi hỏi nhiều công sức tinh chỉnh để đạt độ chính xác cao. Vì vậy, nhiều doanh nghiệp tại Việt Nam chuyển sang các giải pháp OCR ứng dụng trí tuệ nhân tạo, dễ triển khai hơn và vẫn đảm bảo chạy nội bộ để bảo mật dữ liệu.
OCR Studio được xem là bước nâng cấp thực tế từ Tesseract, đặc biệt phù hợp với các bài toán xử lý tài liệu tiếng Việt trong môi trường doanh nghiệp. Sản phẩm được nghiên cứu và phát triển bởi đội ngũ kỹ sư AI tại GMO-Z.com RUNSYSTEM. Giải pháp này hướng tới việc nâng cao độ chính xác nhận dạng, tối ưu hiệu suất xử lý và đáp ứng các nhu cầu xử lý tài liệu phức tạp trong thực tế.
OCR Studio là hệ thống OCR dựa trên trí tuệ nhân tạo (kết hợp thị giác máy tính và học sâu), cho phép:
So với Tesseract, OCR Studio nổi bật ở:
Khi nào nên nâng cấp từ Tesseract lên OCR Studio?
Giải pháp này phù hợp cho môi trường vận hành thực tế nhờ tính ổn định và khả năng triển khai nhanh, tuy nhiên mức độ linh hoạt sẽ thấp hơn Tesseract trong các trường hợp cần can thiệp sâu vào pipeline OCR hoặc nghiên cứu, thử nghiệm thuật toán. OCR Studio không phải giải pháp miễn phí như Tesseract, nhưng đổi lại giúp giảm đáng kể thời gian triển khai và công sức tinh chỉnh hệ thống.
Với các dự án cá nhân hoặc giai đoạn thử nghiệm nhỏ, Tesseract vẫn là lựa chọn tiết kiệm và chủ động. Khi hệ thống mở rộng lên quy mô doanh nghiệp và yêu cầu độ ổn định cao, OCR Studio trở thành phương án nâng cấp hợp lý và thực tiễn hơn.

OCR Studio: Bước nâng cấp thực tế từ OCR mã nguồn mở như Tesseract
Câu hỏi 1: Các lỗi phổ biến khi dùng pytesseract và cách khắc phục
Dưới đây là 4 lỗi thường gặp khi dùng pytesseract và hướng dẫn cách khắc phục:
Câu hỏi 2: Tesseract có nhận dạng chữ viết tay không?
Khả năng nhận dạng chữ viết tay của Tesseract khá hạn chế khi dùng mặc định. Muốn cải thiện cần huấn luyện mô hình riêng với lượng dữ liệu lớn, tốn nhiều thời gian và công sức. Trong trường hợp cần xử lý chữ viết tay, nên cân nhắc các công cụ chuyên biệt cho tiếng Việt.
Câu hỏi 3: Huấn luyện Tesseract cho font tiếng Việt đặc thù như thế nào?
Tesseract cho phép huấn luyện thêm bằng bộ công cụ huấn luyện chính thức. Quá trình này yêu cầu ảnh và văn bản chuẩn tương ứng, sau đó huấn luyện mô hình LSTM và xuất dữ liệu sử dụng. Tại Việt Nam, nhiều dự án huấn luyện cho hóa đơn hoặc giấy tờ tùy thân đã giúp tăng đáng kể độ chính xác.
Câu hỏi 4: Khi nào nên chuyển sang công cụ OCR khác?
Nếu đã tinh chỉnh nhưng kết quả vẫn chưa đạt yêu cầu, bạn nên cân nhắc các công cụ OCR thế hệ mới cho độ chính xác cao hơn, đặc biệt với tiếng Việt. Với người dùng không chuyên kỹ thuật hoặc cần giao diện trực quan, các giải pháp OCR thương mại triển khai nội bộ sẽ phù hợp hơn.
Câu hỏi 5: Tesseract còn được cập nhật trong năm 2026 không?
Có. Tesseract vẫn được cộng đồng mã nguồn mở duy trì và tiếp tục nhận các bản vá lỗi trong nhánh 5.x (ra mắt năm 2021). Tuy nhiên, kiến trúc lõi vẫn dựa trên LSTM và không có thay đổi lớn trong các bản cập nhật gần đây. So với các hệ thống OCR mới dựa trên deep learning và Vision-Language Models (VLM), Tesseract hiện không còn nhiều đột phá về công nghệ.
Tóm lại, OCR Tesseract vẫn là lựa chọn phù hợp cho các bài toán OCR cơ bản, chi phí thấp và yêu cầu chạy offline. Tuy nhiên, với những dự án doanh nghiệp cần độ chính xác cao, xử lý tài liệu tiếng Việt phức tạp và triển khai ổn định, việc nâng cấp lên các giải pháp OCR ứng dụng trí tuệ nhân tạo như OCR Studio sẽ giúp tiết kiệm đáng kể thời gian và nguồn lực. Liên hệ đội ngũ OCR Studio để được tư vấn giải pháp OCR phù hợp, trải nghiệm demo thực tế và lựa chọn hướng triển khai tối ưu cho hệ thống của bạn.











